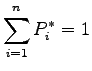Next: Local Energy and its
Up: Re-sampling methods
Previous: Re-sampling methods
Contents
Jackknife
Now we briefly describe how it is possible to obtain the standard deviation of a generic estimator using the Jackknife method. For simplicity we consider the average estimator.
Let us consider the variables:
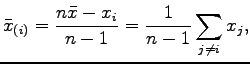 |
(A.3) |
where 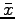 is the sample average.
is the sample average. 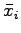 is the sample average of the data set deleting the ith point. Then we can define the average of
:
is the sample average of the data set deleting the ith point. Then we can define the average of
:
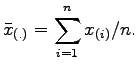 |
(A.4) |
The jackknife estimate of standard deviation is then defined as:
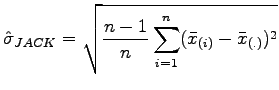 |
(A.5) |
The advantage of this formula is that it can be used for any estimator, and it reduces to the usual standard deviation for the mean value estimator.
In this thesis we always used the Jackknife re-sampling method. Here we want to show that
the connection between the Jackknife and another very used re-sampling method the Bootstrap.
Consider a generic estimator 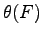 evaluated on set of data
evaluated on set of data
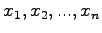 of the unknown distribution
of the unknown distribution 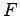 . Let us take a re-sampling vector
. Let us take a re-sampling vector
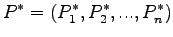 |
(A.6) |
such that
in other words, a probability vector. We can re-weight our data sample with the vector 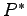 and then evaluate the estimator
and then evaluate the estimator
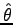 on the re-sampled data:
on the re-sampled data:
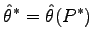 |
(A.7) |
The difference between Bootstrap and Jackknife is in the choice of this re-sampling probability vector. In the Bootstrap we use:
 |
(A.8) |
while in the Jackknife
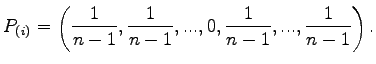 |
(A.9) |
The estimate of the standard deviation is then given by eq. A.2, for a good discussion about Jackknife, Bootstrap and other re-sampling methods see Ref. (109).
Next: Local Energy and its
Up: Re-sampling methods
Previous: Re-sampling methods
Contents
Claudio Attaccalite
2005-11-07