



Next: Jackknife
Up: thesis
Previous: Future developments
Contents
Re-sampling methods
There is a simple motivation to use re-sampling methods. In fact let us consider a set of independent and identically distributed data samples 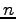 of an unknown probability distribution
of an unknown probability distribution 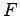 :
:
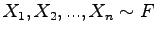 |
(A.1) |
We can compute the sample average
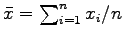 , and then we can estimate the accuracy of
, and then we can estimate the accuracy of 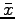 using the standard deviation:
using the standard deviation:
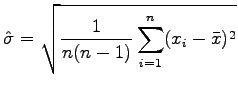 |
(A.2) |
The trouble with this formula is that it does not, in any obvious way, extend to estimators other than
. For this reason a generalized version of A.2 is introduced such that it reduces to the usual standard deviation when the chosen estimator is the average.
Subsections
Claudio Attaccalite
2005-11-07